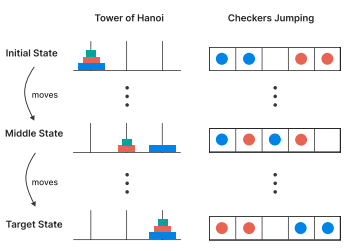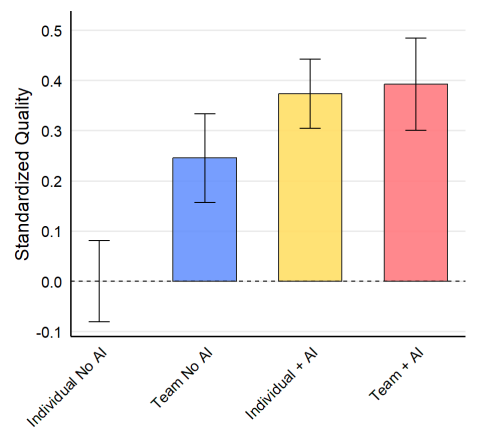
Beneficios de la IA en el trabajo en equipo
Este estudio experimental en Procter & Gamble revela que la IA Generativa está transformando el trabajo en equipo. Demuestra que individuos que utilizan IA igualan el rendimiento de equipos humanos sin ella, sugiriendo que la IA puede replicar beneficios de la colaboración. La IA también democratiza la expertise, permitiendo a profesionales de diferentes áreas crear …